반응형
$url = "https://www.fmkorea.com/best/9702483339"
node -e "const { chromium } = require('playwright'); const fs = require('fs'); const https = require('https');
const url = '$url';
function safe(u){
return u.replace(/https?:\/\//,'').replace(/[^a-zA-Z0-9]/g,'_');
}
(async () => {
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto(url, { waitUntil: 'domcontentloaded', timeout: 60000 });
await page.waitForTimeout(5000);
const folder = safe(url);
fs.mkdirSync(folder, { recursive: true });
await page.screenshot({
path: folder + '/page.png',
fullPage: true
});
const media = await page.evaluate(() => {
const imgs = Array.from(document.querySelectorAll('img')).map(i => i.src);
const vids = Array.from(document.querySelectorAll('video')).map(v => v.src);
const srcs = Array.from(document.querySelectorAll('source')).map(s => s.src);
const frames = Array.from(document.querySelectorAll('iframe')).map(i => i.src);
return [...imgs, ...vids, ...srcs, ...frames].filter(Boolean);
});
const clean = media.filter(u =>
u &&
!u.includes('googleads') &&
!u.includes('doubleclick') &&
!u.includes('recaptcha') &&
!u.includes('about:blank')
);
fs.writeFileSync(folder + '/media.txt', clean.join('\\n'));
let i = 1;
for (const u of clean) {
if (!u.includes('.mp4')) continue;
const file = fs.createWriteStream(folder + '/video_' + i + '.mp4');
https.get(u, (res) => res.pipe(file));
i++;
}
console.log('DONE:', folder);
await browser.close();
})();"
제가 만든 코드입니다
특정 주소의 전체 캡쳐본과
캡쳐본으로는 담아지지 않는 영상 다운로드 기능까지 포함한 코드입니다
자동으로 수많은 콘텐츠를 다운할수있습니다
추가적으로 자동 주소 추가 다운로드 기능 등도 가능하며
본인 윈도우 환경이 달라서 안되는 부분들 최적화 까지 모두 작업의뢰 가능합니다
카카오톡 deni1 으로 친구추가하시고 연락주세요
node -e "const { chromium } = require('playwright'); const fs = require('fs'); const https = require('https');
function safe(u){
return u.replace(/https?:\/\//,'').replace(/[^a-zA-Z0-9]/g,'_');
}
(async () => {
const browser = await chromium.launch();
const page = await browser.newPage();
// 1. BEST 페이지 접속
await page.goto('https://www.fmkorea.com/best', {
waitUntil: 'domcontentloaded',
timeout: 60000
});
await page.waitForTimeout(5000);
// 2. 글 링크 전부 수집
const links = await page.evaluate(() => {
return Array.from(document.querySelectorAll('a'))
.map(a => a.href)
.filter(h => h && h.includes('/best/') && h.split('/').length > 4);
});
const unique = [...new Set(links)];
console.log('FOUND POSTS:', unique.length);
// 3. 각 글 처리
for (const url of unique.slice(0, 10)) { // ⚠️ 안전상 10개 제한
const folder = safe(url);
fs.mkdirSync(folder, { recursive: true });
const p = await browser.newPage();
try {
await p.goto(url, { waitUntil: 'domcontentloaded', timeout: 60000 });
await p.waitForTimeout(5000);
// screenshot
await p.screenshot({
path: folder + '/page.png',
fullPage: true
});
// media 추출
const media = await p.evaluate(() => {
const imgs = Array.from(document.querySelectorAll('img')).map(i => i.src);
const vids = Array.from(document.querySelectorAll('video')).map(v => v.src);
const srcs = Array.from(document.querySelectorAll('source')).map(s => s.src);
const frames = Array.from(document.querySelectorAll('iframe')).map(i => i.src);
return [...imgs, ...vids, ...srcs, ...frames].filter(Boolean);
});
const clean = media.filter(u =>
u &&
!u.includes('googleads') &&
!u.includes('doubleclick') &&
!u.includes('recaptcha') &&
!u.includes('about:blank')
);
fs.writeFileSync(folder + '/media.txt', clean.join('\\n'));
// mp4 download
let i = 1;
for (const u of clean) {
if (!u.includes('.mp4')) continue;
const file = fs.createWriteStream(folder + '/video_' + i + '.mp4');
https.get(u, (res) => res.pipe(file));
i++;
}
console.log('DONE:', url);
} catch (e) {
console.log('FAIL:', url);
}
await p.close();
}
await browser.close();
})();"
위코드는 기능 확장판입니다
/best 부분의 주소들을 수정해가며 작업하면되고
해당 페이지의 글 20개를 자동으로 수집합니다
이후 html mp4 img 등을 이용해서 하나의 웹페이지로 복원 리딩하는것도 가능합니다
하나의 exe 파일로 압축해 놓았습니다
테스트실행 정도는 가능할 것 같습니다
본인 윈도우 환경에 따라 안 될수는 있습니다
@"
const { chromium } = require('playwright');
const fs = require('fs');
const https = require('https');
function safe(u){
return u.replace(/[\\\\/:*?"<>|]/g,'_');
}
(async () => {
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://www.fmkorea.com/best', {
waitUntil: 'domcontentloaded',
timeout: 60000
});
await page.waitForTimeout(5000);
const links = await page.evaluate(() => {
return Array.from(document.querySelectorAll('a'))
.map(a => a.href)
.filter(h => h && h.includes('/best/') && h.split('/').length > 4);
});
const unique = [...new Set(links)];
console.log('FOUND POSTS:', unique.length);
for (const url of unique.slice(0, 20)) {
const p = await browser.newPage();
try {
await p.goto(url, { waitUntil: 'domcontentloaded', timeout: 60000 });
await p.waitForTimeout(3000);
const data = await p.evaluate(() => {
const title =
document.querySelector('.np_18px_span')?.innerText ||
document.querySelector('h1')?.innerText ||
'no_title';
const like =
document.querySelector('.voted_count')?.innerText ||
document.querySelector('.count')?.innerText ||
'0';
return {
title: title.trim(),
like: like.trim()
};
});
const folderName = safe(data.title + '_추천_' + data.like);
fs.mkdirSync(folderName, { recursive: true });
await p.screenshot({
path: folderName + '/page.png',
fullPage: true
});
const media = await p.evaluate(() => {
const imgs = Array.from(document.querySelectorAll('img')).map(i => i.src);
const vids = Array.from(document.querySelectorAll('video')).map(v => v.src);
const srcs = Array.from(document.querySelectorAll('source')).map(s => s.src);
const frames = Array.from(document.querySelectorAll('iframe')).map(i => i.src);
return [...imgs, ...vids, ...srcs, ...frames].filter(Boolean);
});
const clean = media.filter(u =>
u &&
!u.includes('googleads') &&
!u.includes('doubleclick') &&
!u.includes('recaptcha') &&
!u.includes('about:blank')
);
fs.writeFileSync(folderName + '/media.txt', clean.join('\n'));
let i = 1;
for (const u of clean) {
if (!u.includes('.mp4')) continue;
const file = fs.createWriteStream(folderName + '/video_' + i + '.mp4');
https.get(u, (res) => res.pipe(file));
i++;
}
console.log('DONE:', data.title, data.like);
} catch (e) {
console.log('FAIL:', url);
}
await p.close();
}
await browser.close();
})();
"@ | Set-Content crawl.js
계속 업데이트 중입니다. 이제 코드가 길어져서 크롤닷제이에스로 파일을 저장한 뒤에, 노드 크롤닷제이에스로 시작합니다.
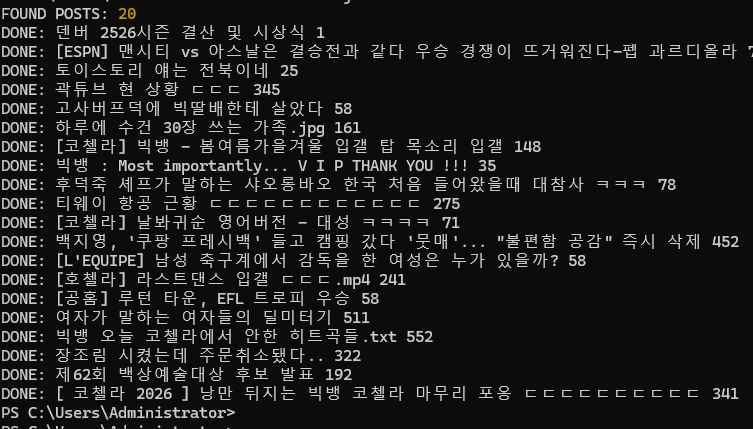
그럼 이런식으로 잘 크롤링됩니다
반응형
'1' 카테고리의 다른 글
| 구글 제미나이 이미지 우하단 워터마크가아닌 표시 제거기 (2) | 2026.04.19 |
|---|---|
| 무조건 경영학과를 가야 하는 이유 – 현실적인 네임밸류 전략 (0) | 2026.04.16 |
| 바이브코딩 시작부터 졸업까지 완벽 총정리 | 안티그래비티, 클로드코드, 정리 pdf 요약 (0) | 2026.04.13 |
| 오늘의 커뮤글 오프라인에서 읽을거리 받아놓기 (0) | 2026.04.13 |
| 백강현이 만든 게임 블라인드 탱크 디시 리뷰와 플레이스토어 해보기 (0) | 2026.04.10 |
| 컨덕턴스 2개를 직렬로 접속하여 3A의 전류를 흘리려면 몇V의 전압을 공급하면 되는가? (0) | 2026.04.01 |
| 전기기능사 면접 핵심 문제 10선 (0) | 2026.04.01 |
| kor_cat 스챗 방송 분석 | 인기 이유, 매력 포인트, 남성 시청자 심리, 반전 매력과 분위기 연출 전략까지 완벽 정리 (0) | 2026.03.29 |
